Inteligencia Artificial
Introducción
Desde hace unos años, la inteligencia artificial se ha ido convirtiendo en una tecnología cada vez más importante en nuestras vidas. Se puede usar para muchas cosas como pedir información, programar, consultar dudas y en definitiva puede ayudarnos en nuestro día a día. Es por ello que hemos decidido implementar inteligencia en nuestro ecosistema, no sólo como un extra sino como un servicio más que nos pueda aportar valor. Para ello montamos un stack completo con modelos locales mediante Ollama y mediante API una API externa de Groq, usando Open WebUI como interfaz para ambos tipos.
Motivos de elección
Originalmente nuestra idea inicial era sólo usar modelos locales para así respetar los pilares de nuestro proyecto: simple, seguro y autoalojado. Es por ello que elegimos Ollama usando Open WebUI y descargamos modelos bastante pequeños como Phi 2.7B y Gemma 2B ya que pensamos que al ser modelos pequeños podríamos correrlo en nuestro servidor y poder mantenerlo todo autoalojado, manteniendo control de nuestros datos y sin depender de terceros. Aprendiendo sobre los modelos mientras los usaremos.
Sin embargo, el rendimiento no fue el esperado con tiempos de respuesta bastante considerables y un gran consumo de CPU. Es por ello, que para no dejar la inteligencia artificial de lado y poder implementarla de manera exitosa en nuestro proyecto decidimos mantener Ollama con los modelos locales para experimentar y para un uso más diario usar la API gratuita de Groq, que nos permite tener modelos más potentes y rápidos de manera gratuita y principalmente liberar a nuestro servidor del procesamiento.
Elegimos Open WebUI como interfaz para nuestra inteligencia artificial y que nos permite cambiar fácilmente entre modelos locales y externos, nos ofrece una interfaz muy limpia y similar a otras inteligencias artificiales y porque es de código abierto la parte que nosotros usamos.
Función dentro del proyecto
Dentro de bitCLD, la inteligencia artificial actúa como nuestro asistente personal para resolver nuestras consultas al estilo ChatGPT o Deepseek pero sin gastar dinero en subscripciones y teniendo la oportunidad de tenerlo en nuestro ecosistema. Gracias a Open WebUI podemos tener una interfaz muy amigable y podemos cambiar muy fácilmente entre nuestros modelos locales y los modelos que nos ofrece Groq.
Mantenemos los modelos locales para así poder demostrar que es posible autoalojar la inteligencia artificial gracias a Docker y para hacer pruebas de cómo funciona todo para que cuando tengamos la oportunidad de tener un servidor más potente ya sepamos como funciona todo.
Por otra parte, usamos Groq para conseguir respuestas más completas y rápidas sin sobrecargar nuestro minipc y también para poder aprender sobre el uso de las APIs y su integración en proyectos como bitCLD.
Instalación
Tanto WebUI y como Ollama los desplegamos fácilmente como contenedor Docker y lo gestionamos desde Dockge, manteniendo la coherencia y modularidad del ecosistema bitCLD.
Desde la interfaz de Dockge, creamos una nueva pila (stack) llamada ia y añadimos el siguiente contenido en su archivo docker-compose.yml:
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- 11434:11434
volumes:
- ollama:/root/.ollama
deploy:
resources:
limits:
cpus: "2.0"
memory: 8G
reservations:
cpus: "1.0"
memory: 6G
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
depends_on:
- ollama
environment:
- OLLAMA_API_BASE=http://ollama:11434
ports:
- 3002:8080
deploy:
resources:
limits:
cpus: "1.0"
memory: 2G
reservations:
cpus: "0.5"
memory: 1G
volumes:
ollama: null
Explicación del docker compose
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
| Parámetro | Descripción |
|---|---|
image: ollama/ollama:latest |
Usa la última versión oficial de la imagen de Ollama desde Docker Hub. |
container_name: ollama |
Asigna un nombre fijo al contenedor (útil para comandos y depuración). |
restart: unless-stopped |
Hace que el contenedor se reinicie automáticamente si se detiene de forma inesperada, salvo que se haya detenido manualmente. |
ports:
- 11434:11434 # puerto interno de Ollama para comunicación con Open WebUI
| Puerto | Descripción |
|---|---|
ports: - 11434:11434 |
Puerto interno de Ollama para comunicación con Open WebUI |
volumes:
- ollama:/root/.ollama
| Volumen | Descripción |
|---|---|
volumes: - ollama:/root/.ollama |
Volumen donde Ollama guarda: Modelos descargados, configuración y datos persistentes |
resources:
limits:
cpus: "2.0" # máximo 2 núcleos
memory: 8G # máximo 8 GB de RAM
reservations:
cpus: "1.0"
memory: 6G
| Parámetro | Descripción |
|---|---|
limits: cpus: "2.0" |
Indica que este contenedor no debería usar más de 2 CPU lógicas |
memory: 8G |
Indica que un límite máximo de 8 GB de RAM para este contenedor |
reservations:cpus: "1.0" |
Reserva 1 CPU lógica “prioritaria” para este contenedor |
memory: 6G |
reserva 6 GB de RAM para él |
Este bloque indica restricciones de recursos. Sin embargo, es posible que algunos de estos parámetros no se apliquen pero nos sirve como referencia para saber cúantos recursos estamos dispuestos a usar en este servicio.
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
| Parámetro | Descripción |
|---|---|
image: ghcr.io/open-webui/open-webui:main |
Se usa la imagen de Open WebUi y se descarga desde el registry de GitHub Container Registry de la rama principal del proyecto |
container_name: open-webui |
Asigna un nombre fijo al contenedor (útil para comandos y depuración). |
restart: unless-stopped |
Hace que el contenedor se reinicie automáticamente si se detiene de forma inesperada, salvo que se haya detenido manualmente. |
depends_on:
- ollama
| Parámetro | Descripción |
|---|---|
depends_on: - ollama |
Indica que este servicio depende de ollama por lo que docker arrancará primero ollama luego levantará open-webui |
environment:
- OLLAMA_API_BASE=http://ollama:11434
| Environment | Descripción |
|---|---|
environment: - OLLAMA_API_BASE=http://ollama:11434 |
Indica URL base de la API de Ollama con el nombre del contenedor y el puerto interno de la API |
Gracias a esta variable, Open WebUI sabe a dónde debe acudir para usar modelos de Ollama.
ports:
- 3002:8080 # puerto del host que usarás para acceder desde navegador o Cloudflare
| Puerto | Descripción |
|---|---|
ports: - 3002:8080 |
Puerto del host que se usará en el navegador, Cloudflare y Caddy |
deploy:
resources:
limits:
cpus: "1.0" # máximo 1 núcleo
memory: 2G # máximo 2 GB de RAM
reservations:
cpus: "0.5"
memory: 1G
| Parámetro | Descripción |
|---|---|
limits: cpus: "1.0" |
Indica que este contenedor no debería usar más de 1 CPU lógicas |
memory: 2G |
Indica que un límite máximo de 2 GB de RAM para este contenedor |
reservations:cpus: "0.5" |
Reserva 1 CPU lógica “prioritaria” para este contenedor |
memory: 1G |
reserva 1 GB de RAM para él |
volumes:
ollama: null
| Volumen | Descripción |
|---|---|
volumes: ollama: null |
Docker creará un volumen persistente llamado ollama con datos persistentes |
Configuración
Una vez lo hayamos desplegado e iniciado desde Dockge podremos acceder a http://192.168.1.5:3002 para configurarlo.
Crear cuenta de administrador
Una vez iniciemos el servicio por primera vez crearemos una cuenta, la cuál se convertirá en la de administrador. Después podremos bloquear que se creen nuevas cuentas:
Los datos que pongamos se quedarán en local, por lo que no será necesario verificar el correo.
Una vez creado ya tendremos nuestra cuenta de administrador
Verificar la conexión de Open WebUI con Ollama
Al añadir OLLAMA_API_BASE=http://ollama:11434 Ollama ya debería estar conectada con Open WebUI pero debemos asegurarnos para poder proseguir.
-
Nos aseguramos que ollama está corriendo accediendo a
192.168.1.5:11434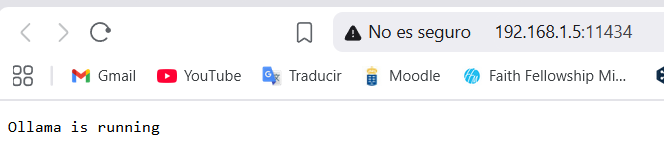
-
Ahora dentro de Open WebUI como administrador accedemos a Ajustes > Ajustes de admin > Conexiones Podremos ver una conexión en API Ollama apuntando a
http://ollama:11434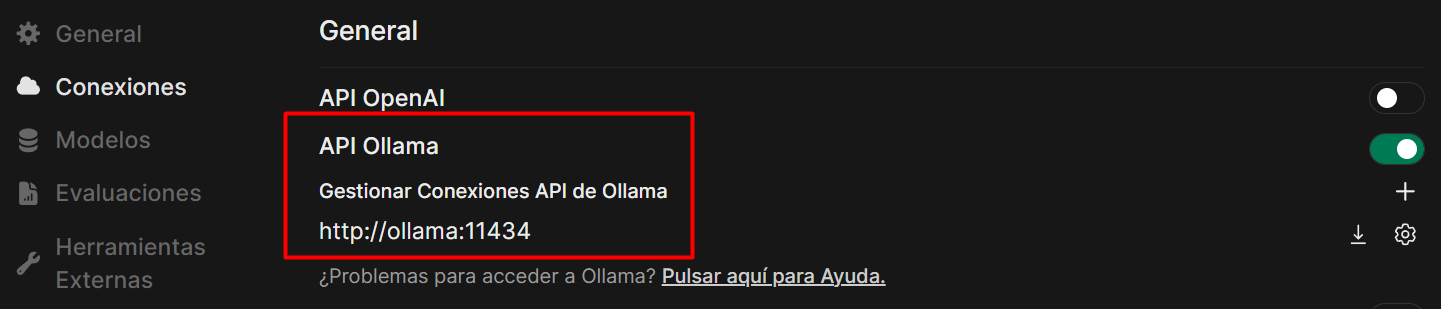
Descargar modelos locales
Una vez nos hayamos asegurado que existe conexión entre ollama y Web UI procederemos a descargar modelos locales para correrlos en nuestro servidor.
Debido a las limitaciones de nuestro equipo descargaremos modelos pequeños como Phi ~2.7B o Gemma ~2B
Para la descarga de los modelos es muy sencilla,
-
Deberemos entrar dentro del contenedor de Ollama mediante ssh y poniendo el siguiente comando:
docker exec -it ollama bash
-
Descargaremos los modelos que consideremos mediante el comando
ollama pull nombre-del-modeloPara encontrar modelos podemos usar la web oficial de ollama
https://ollama.com/search -
Para poder ver los modelos que tenemos descargados usaremos el comando
ollama list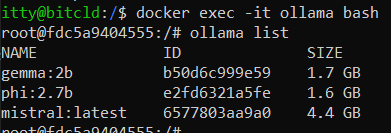
En nuestro caso, nuestro primer intento fue con mistral pero era exageradamente grande para poder correrlo en nuestro servidor.
-
Y salimos del contenedor con
exit
Probar los modelos
Una vez descargados los modelos, ya podremos acceder uso de ellos desde la interfaz de Open WebUI
1. Primer intento
Para nuestro primer intento usaremos Phi 2.7B, por lo que hacemos una consulta simple:
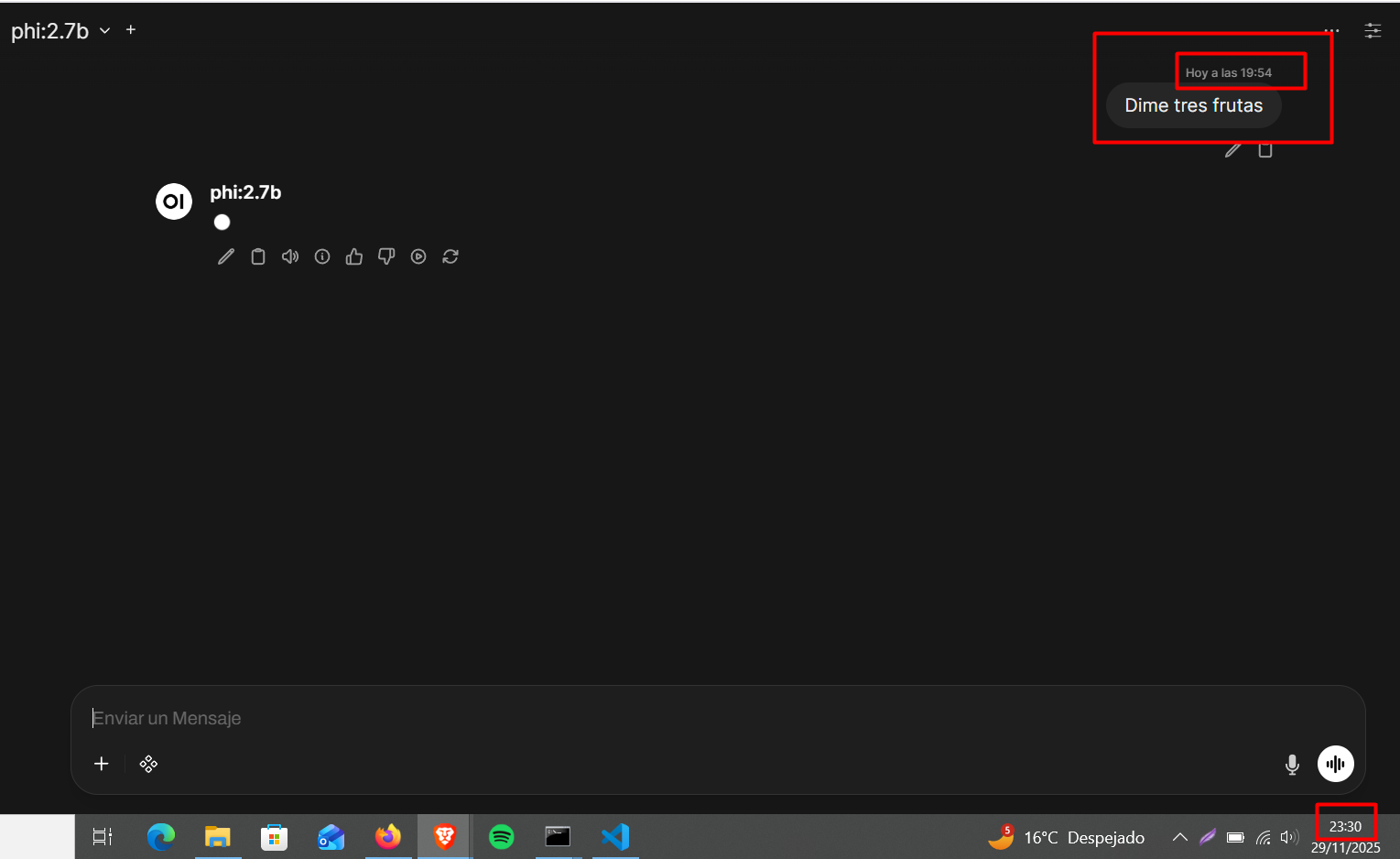
Con este modelo no pudimos obtener ninguna respuesta, incluso esperando por varias horas. Habiendo hecho la consulta a las 19:54 y no obteniendo respuesta a las 23:30, por lo que definitivamente no es un modelo viable para nuestro servidor.
2. Segundo intento
Para nuestra segunda consulta usamos el modelo de Gemma esperando tener un mejor resultado

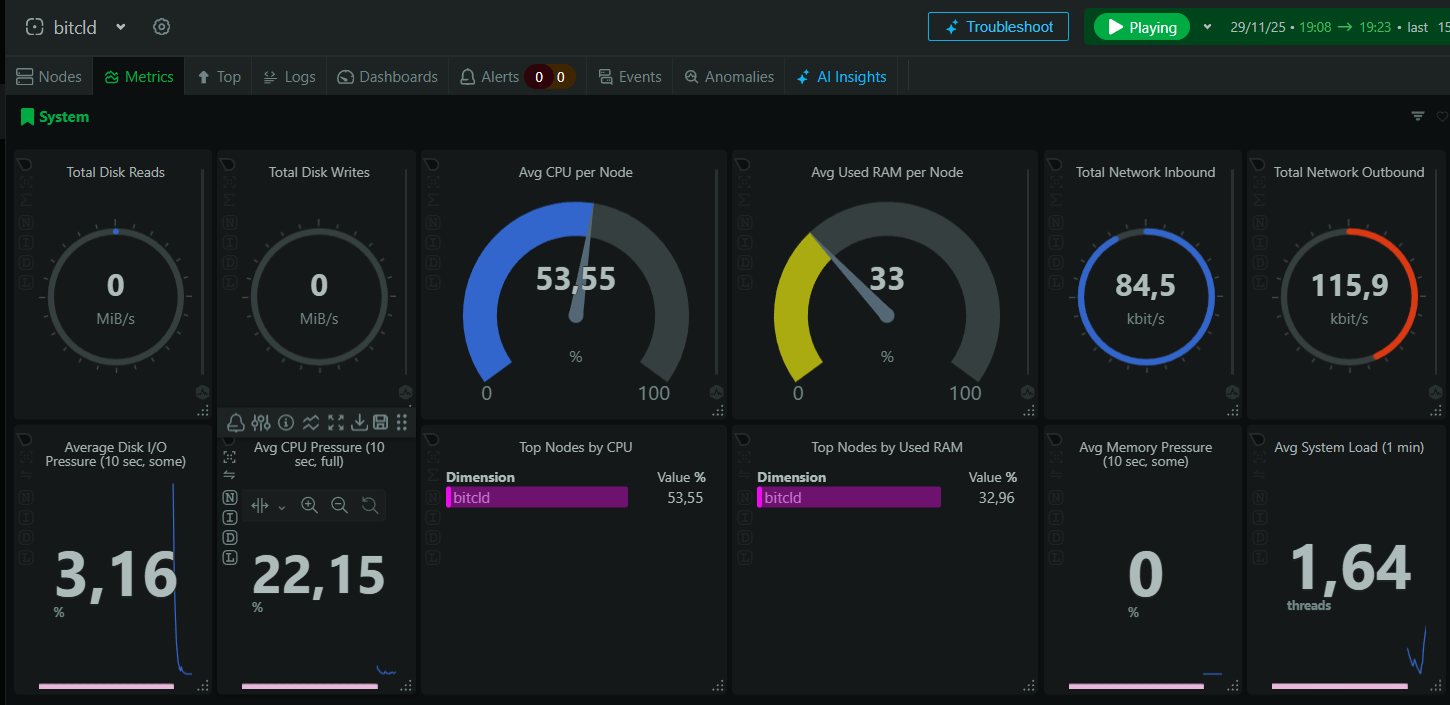
Con este modelo obtuvimos una respuesta con unos 35 segundos de espera, por lo que será el modelo que usemos de manera local. Sin embargo, para un uso normal y cotidiano no es viable, además de que es una gran carga para nuestro servidor:
Esta es una captura de Netdata segundos antes de las consultas:
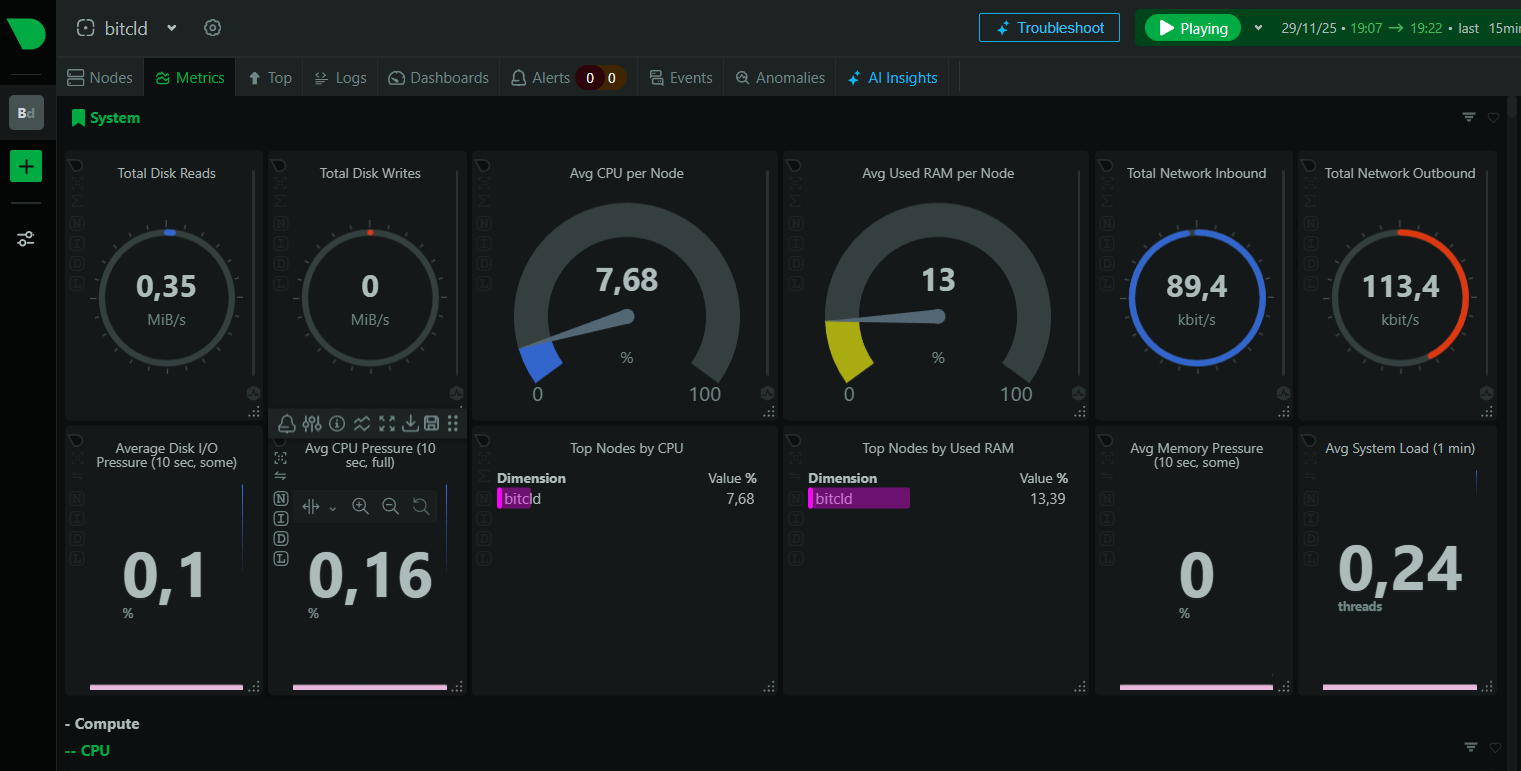
Y esta durante la consulta:
API
Para poder tener una experiencia más fluida y más parecida a un ChatGPT o Deepseek, hemos decidido implementar una API para que nuestro servidor sea simplemente el cliente y todo el procesamiento lo haga otro servidor. De esta manera obtendremos las ventajas de un chat mucho más ágil y sobretodo la oportunidad de poder seguir trabajando con Inteligencia Artificial y poder aprender más sobre el funcionamiento de las APIs. Sin embargo, al utilizar otros servidores para el procesamiento ya no será completamente autoalojado y perderemos el control completo de nuestros datos ya que se encargará otro servidor de realizar la consulta. Algo bastante relevante que tenemos que tener en cuenta.
Elección de API
La elección de qué API escoger fue bastante secilla, ya que al contrario que otras como ChatGPT o Deepseek por las que tienes que pagar, Groq nos da la oportunidad de tener todas las ventajas de usar una API profesional, la cual es compatible con OpenAI, pero sin tener que desembolsar nada siempre que no superemos un límite. Es por ello que elegimos la API de Groq para trabajar en nuestro proyecto.
1. Conseguir API de Groq
Para conseguir la API de Groq deberemos crearnos una cuenta y acceder a https://console.groq.com/keys
Una vez dentro haremos clic en + Create API Key y seleccionaremos un nombre para identificarla

La copiamos
Es muy importante que la copiemos en este paso, ya que una vez creada ya no podremos acceder a ella de nuevo.
Y ya tendremos nuestra API
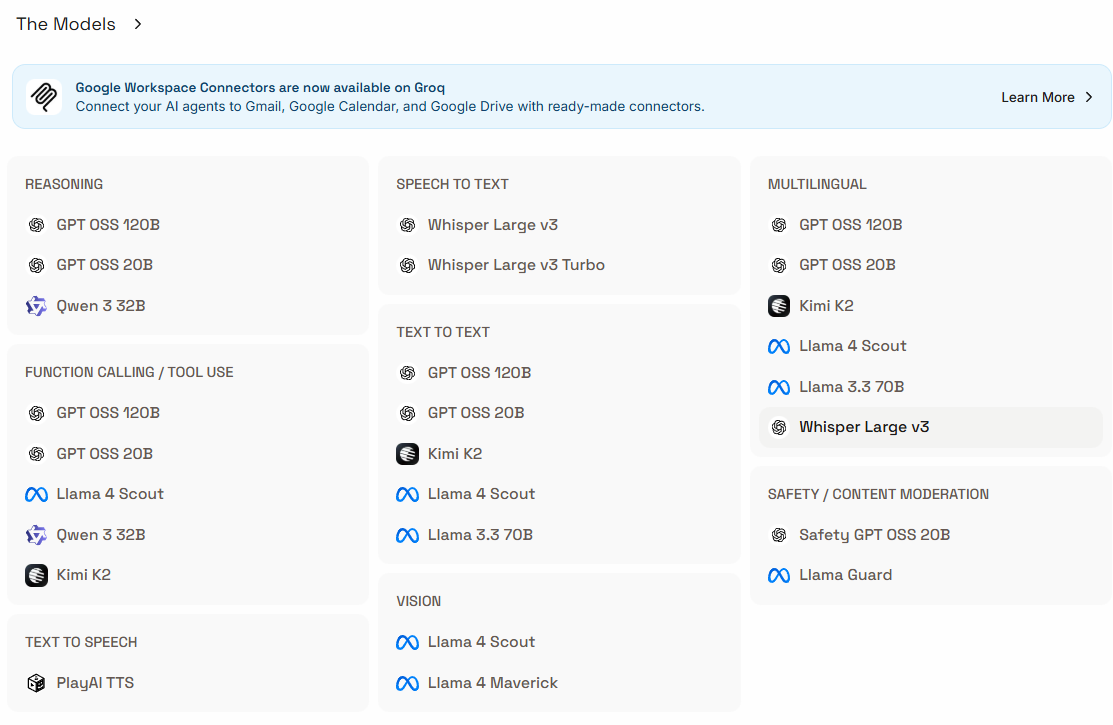
Con esta API gratuita podremos tener acceso a los siguientes modelos:
2. Añadir la API a Open WebUI
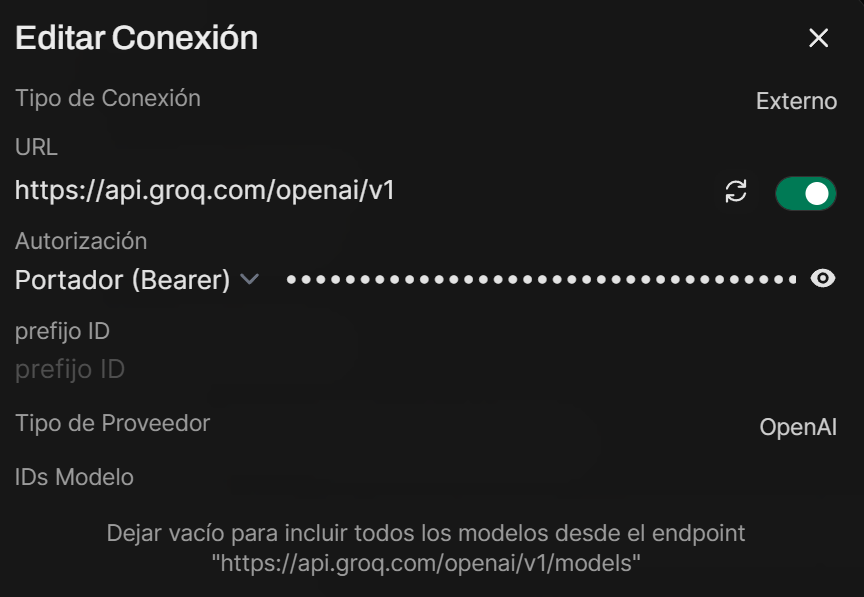
Dentro de Open WebUI volvemos a acceder a Ajustes > Ajustes de admin > Conexiones y en API OpenAI le damos a Añadir Conexión (ya que la API de Groq es compatible con OpenAI). Una vez dentro rellenamos los siguientes campos:
En la documentación oficial encontraremos la URL que deberemos poner https://api.groq.com/openai/v1 y en Autorización añadiremos una API Key
3. Uso de la API de Groq
Una vez añdadida la conexión, podremos acceder a todos los modelos que nos ofrecen (en la captura no aparecen todos)
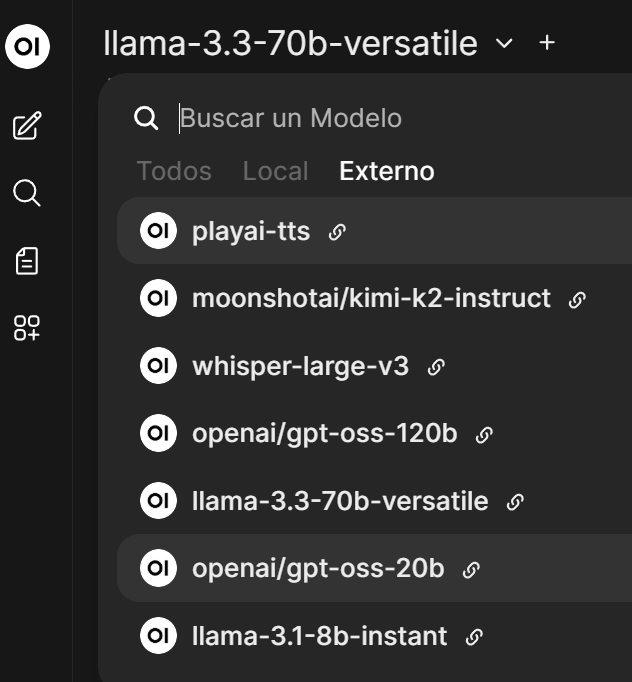
Y al igual que con los modelos locales, seleccionaremos un modelo y le haremos una consulta
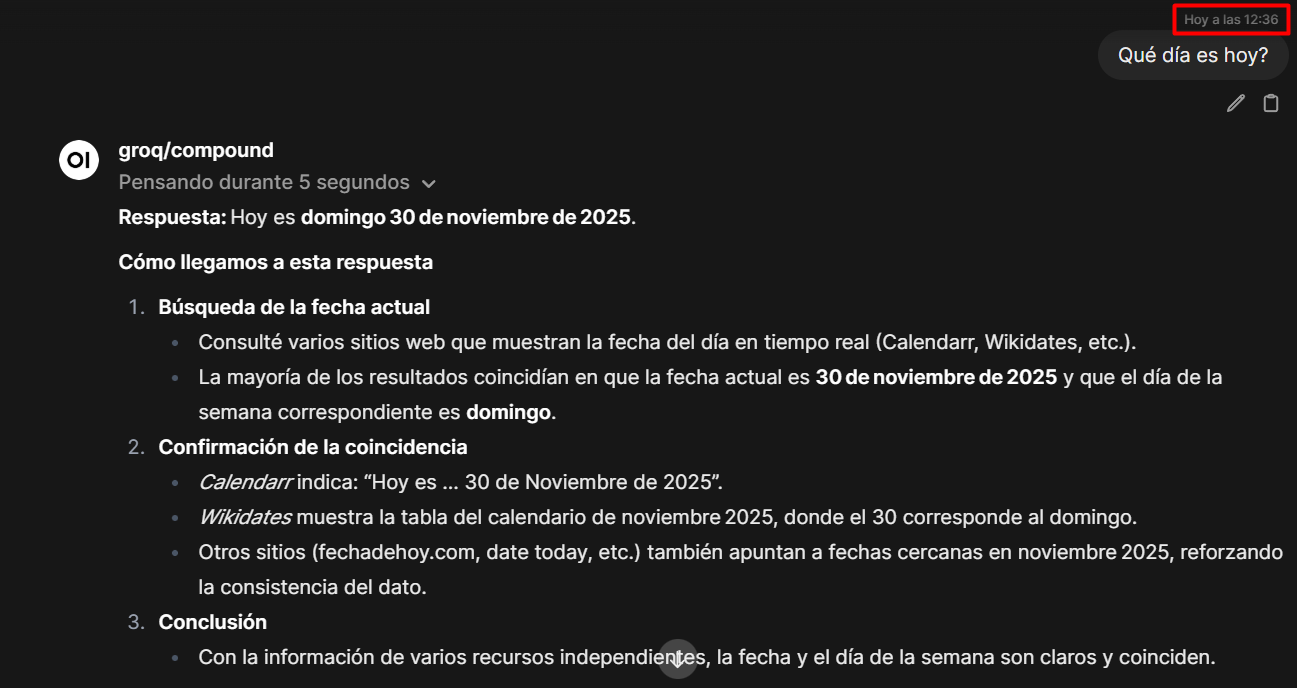
Como resultado obtenemos una respuesta elaborada, precisa y rápida sin nuestro servidor haga el procesamiento
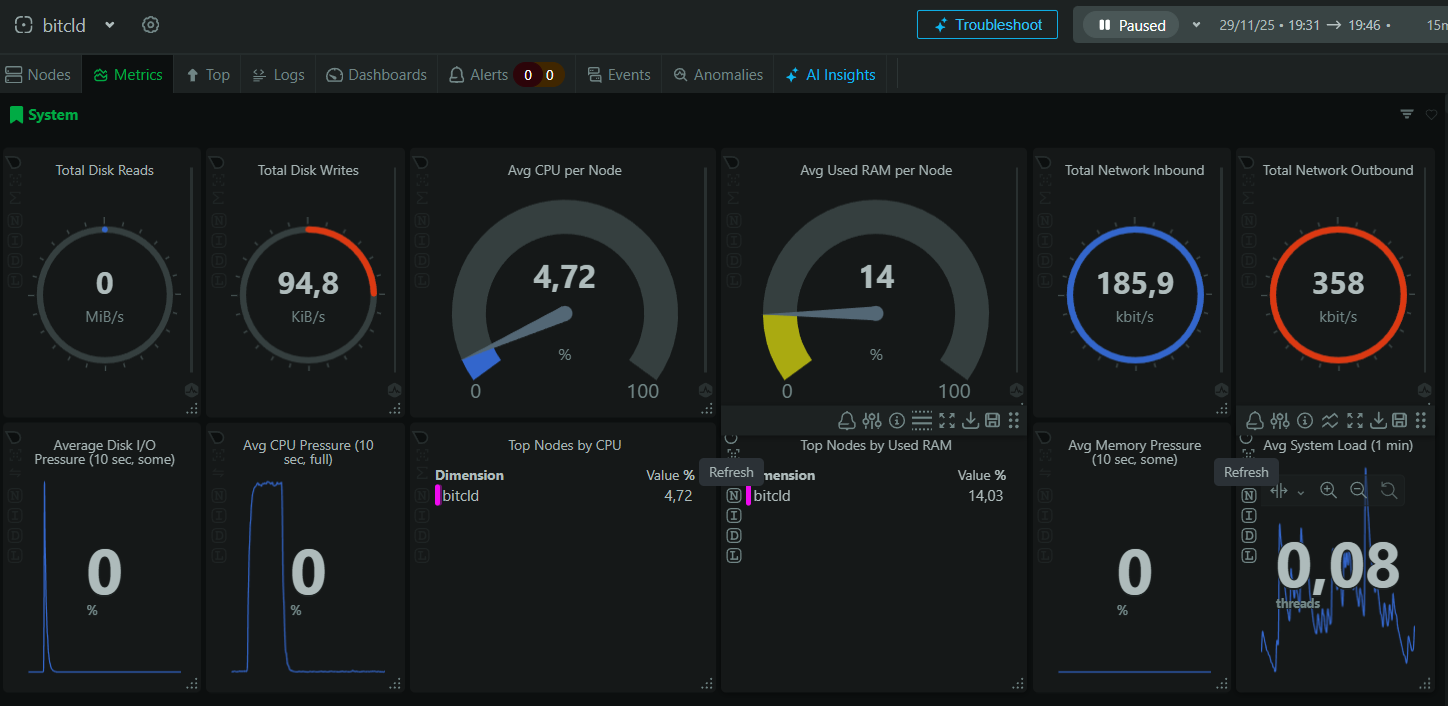
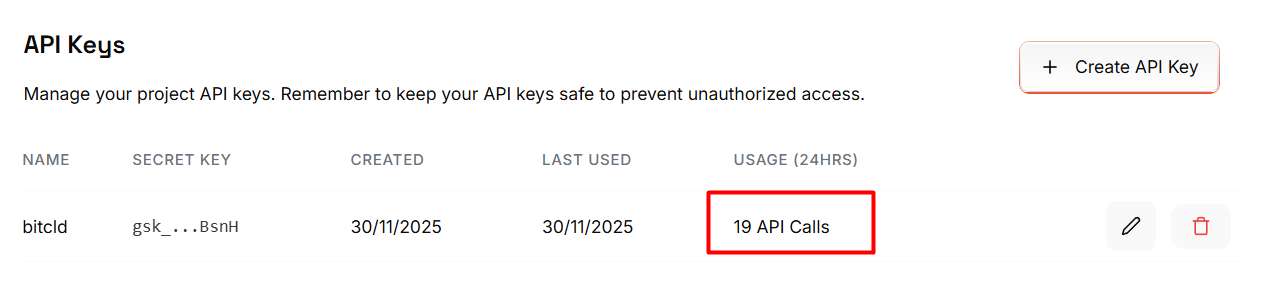
Podemos ver en el panel cómo se ve reflejado el uso que hemos hecho
Conclusión
El integrar la inteligencia artitificial en bitCLD nos ha servido para adaptar nuestro proyectos a tecnologías más modernas y recientes de una manera realista y justificada. Gracias a Ollama y Open WebUI podemos ver cómo se despliegaría la IA de manera completamente local y autoalojada con modelos como Phi y Gemma pero debido a las limitaciones de hardware no pudimos tener una experiencia completamente satisfactoria.
Es por ello que podemos justificar el uso de la API de Groq ya que nos ofrece una mejor experiencia con modelos más potentes y rápidos de una manera gratuita y gracias a Open WebUI podemos usar la misma interfaz tanto para los modelos locales como para los que nos ofrece Groq. Esto nos permite que aunque no hayamos podido cumplir con los tres pilares de manera íntegra. Hemos conseguido que sea simple (al usar la misma interfaz para ambos), es seguro gracias a Caddy Server y Cloudflare + Access, parcialmente autolajoado (ya que sí alojamos Ollama, los modelos y Open WebUI en nuestro servidor) y también parcialmente de código abierto (gracias a Ollama y WebUI).